Machine learning: From “best guess” to best data-based decisions
IBM Causal Inference 360 Toolkit offers access to multiple tools that can move the decision-making processes from “best guess” to concrete answers based on data.

IBM Causal Inference 360 Toolkit offers access to multiple tools that can move the decision-making processes from “best guess” to concrete answers based on data.
Data scientists working with machine learning (ML) have brought us today's era of big data. Traditional ML models are now highly successful in predicting outcomes based on the data. For example, they're good at answering a question such as: “What is my likelihood of developing a specific health condition?”
But ML models are typically not designed to answer what could be done to change that likelihood. This is the concept of causal inference. And until recently, there have been few tools available to help data scientists to train and apply causal inference models, choose between the models, and determine which parameters to use.
At IBM Research, we wanted to change this. Enter the open source IBM Causal Inference 360 Toolkit. Released in 2019, the toolkit is the first of its kind to offer a comprehensive suite of methods, all under one unified API, that aids data scientists to apply and understand causal inference in their models.
We’re excited to unveil the latest in these efforts—a new, customized website for the We are also excited for the Causal Inference Toolkit to mark another step in completing the Trusted AI 360 family of toolkits, including: IBM AI Fairness 360, AI Explainability 360, Adversarial Robustness 360, AI FactSheets 360, and Uncertainty Quantification 360.Causal Inference Toolkit, complete with tutorials, background information, and demos. The demos showcase the package’s abilities in multiple domains, including healthcare, agriculture, and marketing in the financial and banking sectors. We’re also releasing a new version of the open-source Python library with additional functionalities.
All decision-making involves asking questions and trying to get the best answer possible. Take the question: “What happens if I eat eggs every day for breakfast?”
Depending on what is being measured and what additional factors are involved, the answer could vary widely. What if the people who tend to eat eggs for breakfast every morning are also those who work out every morning? Perhaps the difference that we see in the outcome would be driven by the exercise and not by eating eggs.
This is called a confounding variable—affecting both the decision and the outcome. And that’s what causal inference tries to resolve. What is the answer to the question after controlling (as much as possible from the data) for the confounding variable?
Next, we try and account for how the outcome is influenced based on different parameters (for example, how many eggs are eaten; what is eaten with the eggs; is the person overweight, and so on). We can also try and account for what we are looking for (say, whether we are interested if the person would gain weight, or sleep better, or maybe eat less during the day, or lower their cholesterol).
In short, it might be easy to start off with one question that can be answered using data. But to get a reliable answer, we need to fine-tune the parameters involved and the type of model being used.
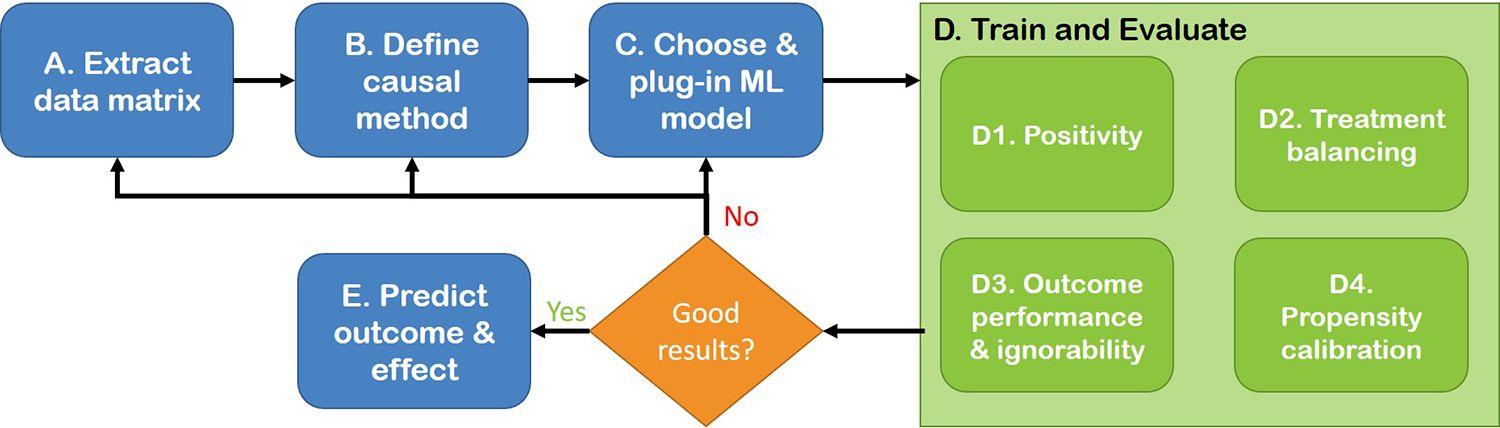
Causal inference consists of a set of methods attempting to estimate the effect of an intervention on an outcome from observational data. With the IBM Causal Inference 360 Toolkit, people can use multiple tools to move their decision-making processes from a “best guess” scenario to concrete answers based on data.
The IBM Causality 360 library is an open-source Python library that uses ML models internally and, unlike most packages, allows users to plug in almost any ML model they want. It also has methodologies to select the best ML models and their parameters based on ML paradigms like cross-validation, and to use well-established and novel causal-specific metrics.
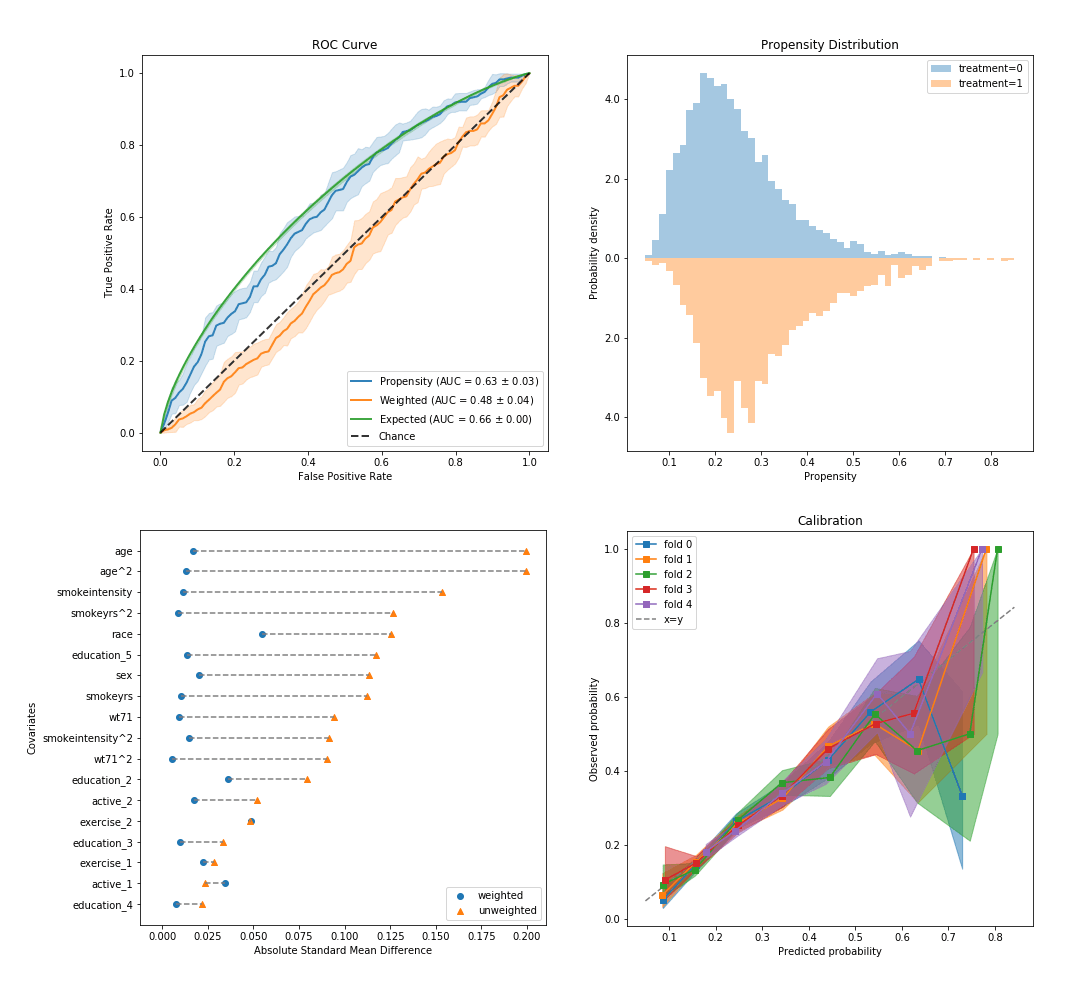
At IBM’s research lab in Haifa, Israel, we have been using the causal inference toolkit as part of our work on drug repurposing.1 Drug repurposing or repositioning is a method for finding new therapeutic uses for accepted drugs. Here, the question we searched for was: “What would happen if patient X took drug Y?”
The result? Discovery of two new potential treatments for dementia that typically accompanies Parkinson’s disease. More specifics on how the causal modeling in this research worked can be found in a blog from April of this year, by our colleague Michal Rosen-Zvi.
The team also used the toolkit in a collaboration with Assuta health services, the largest private network of hospitals in Israel, to analyze the impact of COVID on access to care.2 Specifically, the team analyzed more than 300,000 invitations sent to women for breast screening exams, focusing on instances where the women did not show up for their appointments. The causal inference technology revealed that while at first it seemed the nonpharmaceutical interventions of the government resulted in the no-shows, in reality, it was the number of newly infected people that influenced whether or not the women showed up to their appointments.
In another example, we wanted to understand whether new irrigation practices contribute to a desired reduction in pollution and nutrient runoff. To do this, we used a dataset that captured multiple aspects of the agricultural use of the land, including its irrigation method, and measuring the amount of runoff.
We saw that the data showed little effect. Then we used the causal inference toolkit to correct for the fact that the irrigation methods depend heavily on the type of land use and the type of crop. The outcome changed - we showed that introducing these novel irrigation techniques does reduce runoff. It could save fertilization and water and reduce pollution of the watershed. This reduction can be further quantified to estimate the tradeoff between savings and initial investment.
With the new IBM Causal Inference 360 Toolkit capability and website, we hope to allow people in the field of causal inference to easily apply machine learning methodologies, and to allow ML practitioners to move from asking purely predictive questions to 'what-if' questions using causal inference.
Causality: We study the inference of causal effects and relationships, as well as the application of causal thinking to out-of-distribution generalization, fairness, robustness, and explainability.
Date
01 Sep 2021Notes
- Note 1: We are also excited for the Causal Inference Toolkit to mark another step in completing the Trusted AI 360 family of toolkits, including: IBM AI Fairness 360, AI Explainability 360, Adversarial Robustness 360, AI FactSheets 360, and Uncertainty Quantification 360. ↩︎
References
-
Laifenfeld, D.; Yanover, C.; Ozery-Flato, M.; et al. Emulated Clinical Trials from Longitudinal Real-World Data Efficiently Identify Candidates for Neurological Disease Modification: Examples from Parkinson’s Disease. Front. Pharmacol. (2021). ↩
-
Ozery-Flato, M., Pinchasov, O., Dabush-Kasa, M., et al. Predictive and Causal Analysis of No-Shows for Medical Exams During COVID-19: A Case Study of Breast Imaging in a Nationwide Israeli Health Organization. medRxiv 2021.03.12.21253358, (2021). ↩